赢他科技数据仓库发展之路
赢他科技数据仓库发展之路
本⽂旨在讲述赢他科技在构建企业级数据仓库⽅⾯所做的努⼒和发展历程,以及EMR 数据仓库的应⽤实践,主要内容包括:
数据仓库的建设背景
基于RDS构建数据仓库1.0
基于EMR构建数据仓库2.0
数据仓库的未来规划
⼀、数据仓库的建设背景
公司⾃2013年成⽴以来,⼀直致⼒于打造成新型的集研发、开拓、销售为⼀体的专注于汽配 和家居的B2C跨境电商企业。随着公司快速发展,已拓展了⾃建站、Amazon、eBay、Walmart和Wayfair等诸多销售渠道,包括集散仓、海外⾃建仓以及第三⽅仓等众多仓储系统, 公司业务涵盖产品设计研发、采购、仓储、物流和销售全流程,⽽且业务模式呈多样化。伴随着业务发展,带来的是ERP系统各业务模块数据资产的⾼速增⻓,那么如何治理好公司的数据资产、如何⽀撑⽇益增⻓的数据量以及如何管理好这些数据资产并使其价值变现等,是摆在我们⾯前的⼀系列问题,由此数据仓库等数据理念的引⼊应运⽽⽣,数据仓库的建设势在必⾏。数据仓库的建设能够为我们带来以下益处,主要包括:
公司ERP系统是由基础资料、采购、WMS、TMS、订单以及财务等业务线系统共同组成,每个业务系统有各⾃的数据库,各个系统都有各⾃的数据分析场景,另外再加上数据分析组、运营BI组的数据体系,各个业务线已经形成了数据孤岛,数据管理上烟囱林⽴,⼀定程度造成了资源的浪费,⽽且不利于可持续发展。数据仓库的建⽴,将打破数据孤岛,借助于数据仓库媒介可以统⼀管理公司各业务线的数据资产,形成数据集市,避免资源上的浪费,也便于业务线之间的数据交互。
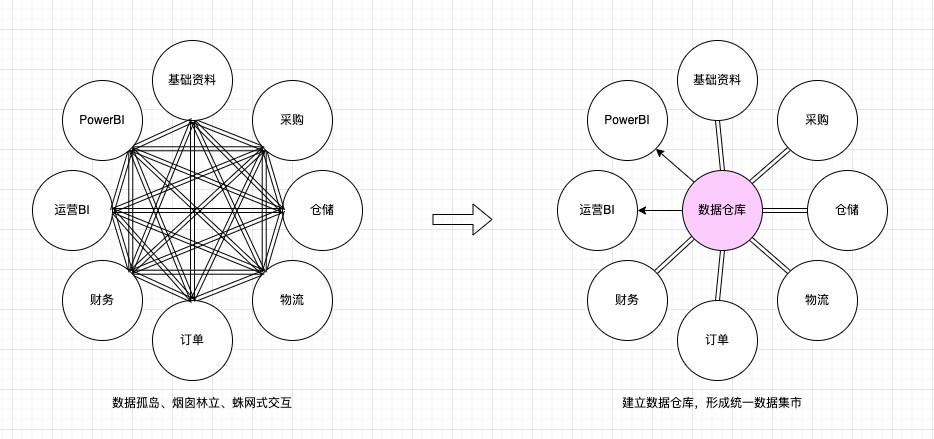
2. 数据⾼度集中,⾯向数据分析提供集成式数据环境
数据仓库对接所有业务线,采集各业务线数据到数据仓库进⾏集中管理,然后再对分析系统提供数据⽀持。如此⼀来:1. 数据分析组以及运营BI组等分析系统,不再需要各⾃对接其他业务线归集数据后进⾏数据分析,避免出现同⼀套数据在多个分析系统中重复存储,进⽽造成资源浪费。由数据仓库作为统⼀的数据出⼊⼝,各分析系统按需接⼊数据仓库建模治理后的数据模型进⾏数据分析;
2. 统⼀数据出⼝,也能够避免同⼀基础指标在不同分析系统中业务⼝径不⼀致,⽽对使⽤⼈员造成困扰;
3. 充分利⽤数据仓库在数据ETL⽅⾯的天然优势,消除以往各分析系统各⾃对接其他业务线的技术壁垒,分析系统仅需聚焦于数据仓库的数据接⼊即可。
3. 数据治理有序,维度清晰,层次分明
数据仓库是⼀个⾯向主题的、集成的、⾮易失的和随时间变化的数据集合。根据⾏业经验,⼀般数据仓库需要承载和⽀持5~10年甚⾄更久的业务发展需要。为了保证数据治理井然有序, 数据仓库是⾯向主题进⾏维度建模,按照传统经典的五层结构进⾏数据层级的划分,另外按照活跃数据以及历史数据进⾏冷热数据分开存储,保证数据易⽤的基础上还不存在数据流失。结合公司的业务形态,我们的数据仓库在以下⽅⾯进⾏数据的治理:
2. 贴合公司业务,按照OA、商品、采购、仓储、物流、订单和财务等主题进⾏划分,各主题下根据具体的业务场景进⾏主题域建模。例如订单主题下按照亚⻢逊销售订单、eBay 销售订单、亚⻢逊退货订单等等主题域进⾏模型设计;
3. 在数据层级划分上,采⽤业内传统⽽经典的五层结构。分别是ODS层、DWD层、DWS 层、DIM层以及ADS层。
1. ODS层作为贴源层能完全还原源系统的业务事实,⽽且保证数据不存在丢失;
2. DWD层作为明细层,会按照主题域进⾏划分,对ODS层的数据进⾏清洗和标准化处理;
3. DWS层作为轻度汇总层,会按主题域对核⼼业务模型进⾏轻度汇总,产出关键性指标;
4. DIM层作为维度层,清晰管理各业务维度;
5. ADS层⾯向数据分析应⽤,按需从各个主题进⾏⾼度聚合统计,满⾜数据分析系统的数据需求
4. 数据资产变现,助⼒决策运营,赋能业务系统
数据仓库不仅仅只是数据集中存储的媒介,⽽更重要的是能让数据产⽣实在的价值:
1. 借鉴⾏业经验,建⽴经典数据模型,输出电商领域关键的业务指标(例如GMV、销售⾦额、⽑利A、库存数量、库存周转率、现⾦流周转率等等),以便于辅助管理层决策。
2. 结合各运营部⻔的业务诉求,建⽴切合部⻔关键能效的数据模型,输出各部⻔所关注的关键业务指标,进⽽辅助运营。例如国内电商⾏业,物流部⻔⽐较关⼼物流作业效率,会对接单、拣货、打包、配送和返回等各个作业环节设计业务指标,⽐如履约及时率、平均拣货时⻓等。
3. 数据仓库包含公司所有业务数据,并且具有完善的数据模型,通过数据同步⼯具进⾏推数或统⼀数据服务⽤于查询等形式,可以向各业务线提供数据⽀持,赋能各个业务线。
4. 数据仓库的模型逐渐完善后,可以进⾏⼀些专项分析,充分开发系统能⼒。例如商品画 像、⽤户画像以及客户群圈定等等,从⽽能够基于这些画像模型在⾃动补货、精细化运营以及精准营销等系统能⼒⽅⾯发⼒。
⼆、基于RDS架构数据仓库1.0
1. RDS数据仓库架构
RDS架构的数据仓库主要采⽤MySQL数据库作为数据存储媒介,数据同步以及数据建模加⼯处理采⽤DataX,源系统库增量数据同步采⽤Tapdata。
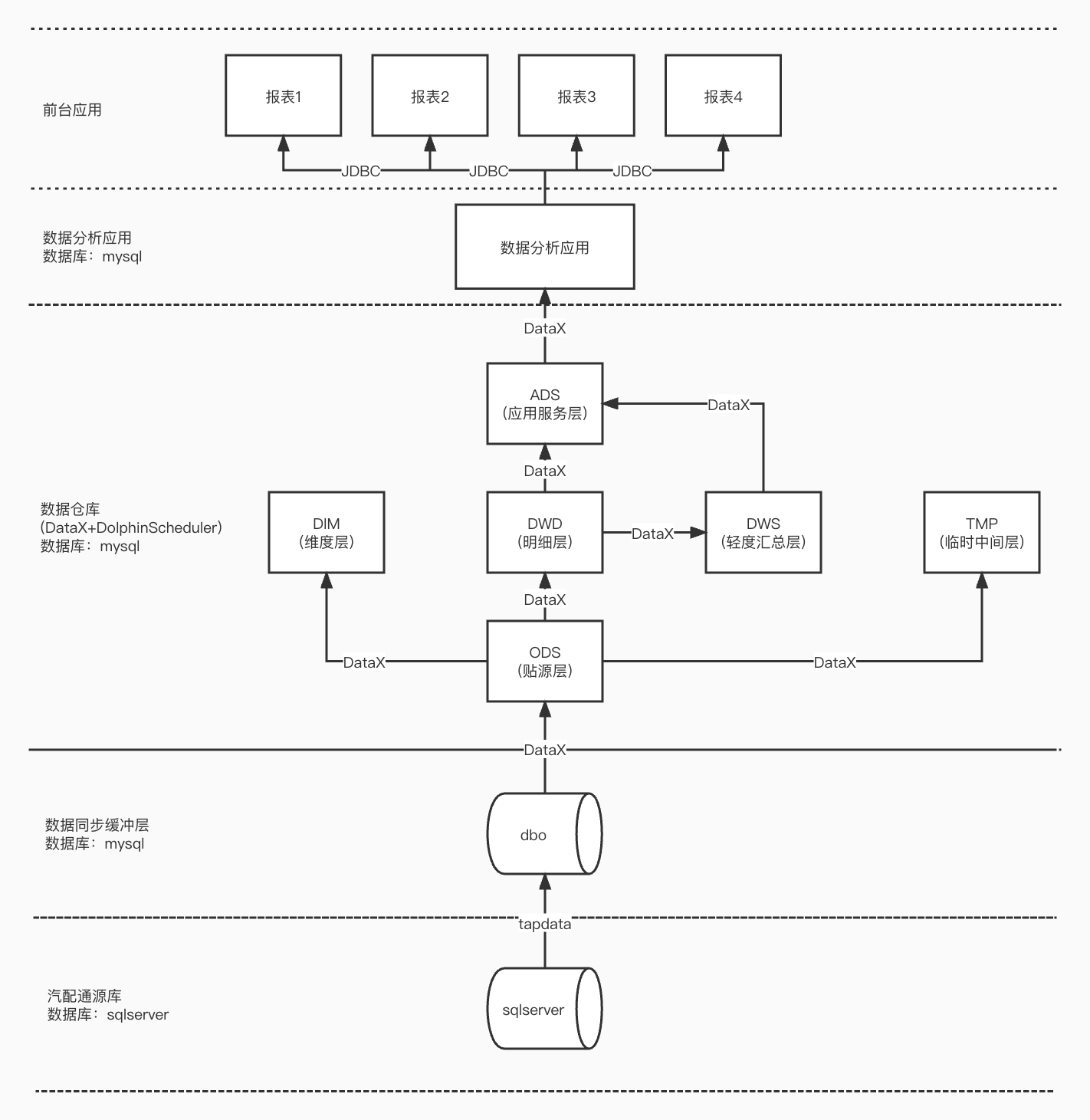
2. RDS数据仓库解决的问题
1. 形成数据仓库雏形,采⽤数据仓库的⽅法论对数据报表相关数据分析功能进⾏实现;
2. 解决OLTP⽅式较难实现诸如进销存数据分析,销售数据分析等问题;
3. 按主题进⾏数据建模,使数据流处理更清晰合理
3. RDS数据仓库存在的不⾜
1. 数据仓库进⾏数据加⼯过程中,如果单表数据量过⼤或者关联表过多时,容易出现MySQL数据库死锁情况;
2. 例如财务主题进销存分析时先进先出的逻辑处理,MySQL缺少窗⼝函数、UDF函数,导致数据处理难度⼤⽽且更复杂;
三、基于EMR架构数据仓库2.0
1. EMR数据仓库架构
使⽤DataX或Hadoop组件Sqoop从源系统同步数据到数据仓库ODS层在S3进⾏存储,然后通过亚⻢逊托管的数据处理集群EMR对数据建模加⼯处理,ADS层数据再通过DataX同步推送到数据分析、BI报表对应的应⽤系统库使⽤。另外,可通过Athena或者Presto⼯具即时查询数据仓库主题数据,从⽽实现OLAP应⽤场景。
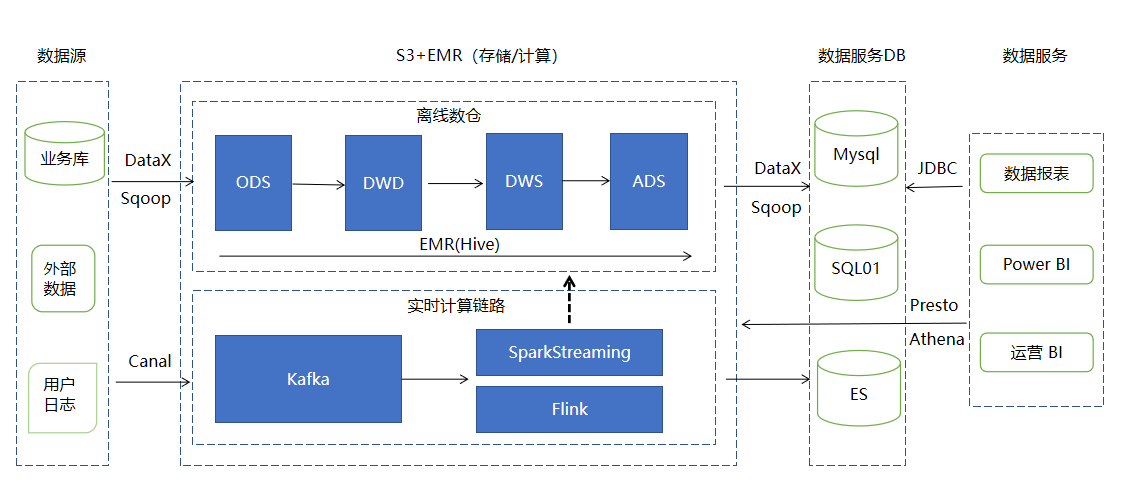
DataX:开源数据同步⼯具,⽀持异构数据库之间的数据同步
Sqoop:EMR中的套件,⽀持结构化数据库和Hive之间的数据同步
Canal:开源数据同步⼯具,⽀持MySQL数据库的增量数据同步
S3:亚⻢逊云提供的对象存储服务
EMR:亚⻢逊云托管式Hadoop集群服务
Presto:EMR中的套件,基于内存的开源SQL引擎,⽐较适合OLAP应⽤场景,弥补Hive在查询性能上的不⾜
2. EMR数据仓库的优势
1. Hive 强⼤的数据处理能⼒,适合离线批处理,能⽀撑⽇益增⻓的数据需求。2. 可使⽤DMS实时同步数据到S3,再通过作业调度,实现分钟级的数据需求
3. 存储、计算分离。可按需扩展,节省费⽤。
3. EMR数据仓库解决的问题
1. 解决RDS架构在⼤数据量时数据库锁死等问题;2. 解决RDS架构数据仓库中窗⼝函数、UDF函数功能缺失的问题;
3. 解决RDS架构数据存储和计算⾼度耦合的问题;
四、数据仓库的发展规划
1. 解决数据分析相关现存的痛点问题
⽬前公司运营BI组、数据分析组以及财务组有⼤量的数据分析需求,现有的处理模式下频繁出现数据处理流程混乱、数据处理稳定性不够以及数据模型设计不完善等痛点问题。随着EMR 数据仓库的建⽴,将通过建⽴完善的数据开发规范、元数据管理规范以及形成数据统⼀标准等形式,设计稳定并且切合实际业务的数据模型,基于DataX+S3+EMR的技术架构,逐步去解 决现存的痛点问题。
2. 完善并丰富数据模型
现阶段所涉及到的主题主要是商品和财务,后续将陆续完善和丰富采购、仓储、物流以及订单主题相关的数据模型,完善数据资产体系。
3. 采⽤Canal+SparkStreaming的模式,打通EMR架构数据仓库实时数据处理链路
现阶段业务需求主要是以天和⼩时级为主,所以采⽤的是离线批处理⽅式构建的数据仓库。随着后续实时性要求的提⾼,我们将采⽤Canal+Spark Streaming的模式打通实时数据链路,完善现有的数据仓库,进⽽满⾜更多的实时数据需求。